近期的topic是mysql相关,之前对于mysql的了解仅限于比较表面的,包括服务停启、搭建、mysql基本语句、mysql数据导入导出、mysql引擎类型等。 mysql topic主要从以下几个方面进行切入,包括整体架构、索引、引擎、primary key、unique key、key、事务操作、锁。
一、b&b+树结构
0x00 b树因何而来
b树是一种树状数据结构。之前对树这块了解都不太多,只听过平衡二叉树、红黑树,这些字面上的意思导致我默认树是两个节点。但是b树打破了我这个偏见。引用july博客的一段话
动态查找树主要有:二叉查找树(Binary Search Tree),平衡二叉查找树(Balanced Binary Search Tree),红黑树(Red-Black Tree ),B-tree/B+-tree/ B*-tree(B~Tree)。前三者是典型的二叉查找树结构,其查找的时间复杂度O(log2N)与树的深度相关,那么降低树的深度自然会提高查找效率。
这段引用提到降低树的深度,那如何降低树的深度呢?想到的就是多叉树,节点多了自然深度就少了。在大规模数据存储方面,大量数据存储在外存磁盘中,而在外存磁盘中读取/写入块(block)中某数据时,首先需要定位到磁盘中的某块,树的深度过大会造成磁盘I/O读写过于频繁,进而导致查询效率低下。如何有效地查找磁盘中的数据,需要一种合理高效的外存数据结构。最终演变为平衡多路查找树结构,即B树以及相关变种结构B+树、B*树等。
0x01 b树结构
B树 - 平衡多路查找树 - 一颗m阶的B树
- 每个结点最多m棵子树
- 除根节点外,其余分支结点至少有[m/2]棵子树
- 根节点至少有两颗子树
- 所有叶节点在同一层上
- 有j个孩子的非叶结点恰好有j-1个关键码,关键码按照递增次序排列
struct BTNode;
typedef struct BTNode *PBTNode;
struct BTNode{
int keyNum; //实际关键字个数
PBTNode parent; //指向父节点
PBTNode *ptr; //子树指针向量
KeyType *key; //关键字向量
}
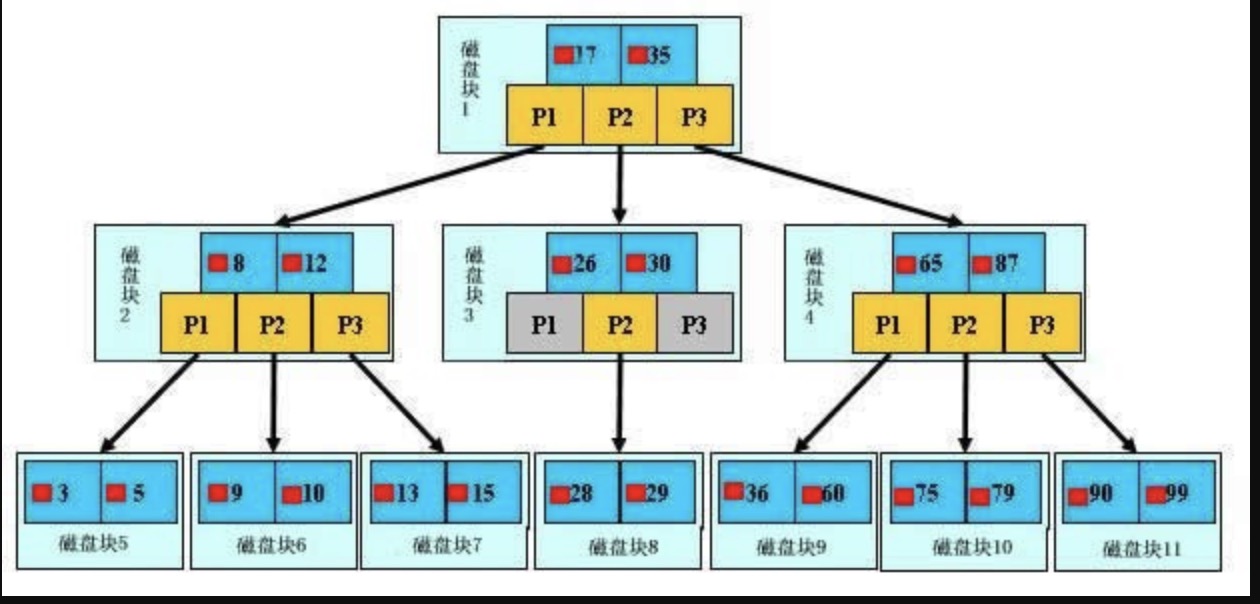
####0x10 b树的查找过程 如上图所示,如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次IO,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过磁盘块1的P2指针的磁盘地址把磁盘块3由磁盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29,结束查询,总计三次IO。真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一次IO,那么总共需要百万次的IO,显然成本非常非常高。
二、复合索引
两个或更多个列上的索引被称作复合索引
利用索引中的附加列,您可以缩小搜索的范围,但使用一个具有两列的索引不同于使用两个单独的索引。
复合索引的结构与电话簿类似,人名由姓和名构成,电话簿首先按姓氏对进行排序,然后按名字对有相同姓氏的人进行排序。
如果您知道姓,电话簿将非常有用;如果您知道姓和名,电话簿则更为有用,但如果您只知道名不姓,电话簿将没有用处。
所以说创建复合索引时,应该仔细考虑列的顺序
举一个复合索引的例子
CREATE TABLE `forum_user_role` (
`id` bigint(20) unsigned NOT NULL auto_increment,
`test_id_1` int(11) unsigned NOT NULL COMMENT '??id',
`test_id_2` int(11) unsigned NOT NULL COMMENT '???id',
`test_id_3` int(11) unsigned NOT NULL COMMENT '???id',
`op_user_id` int(11) unsigned NOT NULL default '0',
`update_time` int(11) unsigned NOT NULL default '0',
`expire_time` int(11) unsigned NOT NULL default '0',
PRIMARY KEY (`id`),
UNIQUE KEY `forum_user_role` (`test_id_1`,`test_id_2`,`test_id_3`),
KEY `forum_role` (`test_id_1`,`test_id_3`),
KEY `user_role` (`test_id_2`,`test_id_3`),
KEY `mis_query` (`test_id_3`,`expire_time`)
) ENGINE=InnoDB AUTO_INCREMENT=490 DEFAULT CHARSET=utf8
复合索引需要注意的点很多,尤其是需要遵循最左前缀匹配原则。该原则会在下一段具体介绍。
三、建立索引的几大原则
- 符合索引的顺序一定要和查询的顺序相同才有效。即最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
- 建表时把需要索引的列定义为非空(not null)
- 查询语句中函数的使用。如果没有使用基于函数的索引,那么where子句中对存在索引的列使用函数时,会使优化器忽略掉这些索引。下面的查询就不会使用索引:
select * from staff where trunc(birthdate) = '01-MAY-82';
但是把函数应用在条件上,索引是可以生效的,把上面的语句改成下面的语句,就可以通过索引进行查找。
select * from staff where birthdate < (to_date('01-MAY-82') + 0.9999);
- 比较不匹配的数据类型也会限制索引的使用
- 索引本身的数据类型尽量选取空间度占用小的
- 尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录
四、explain
0x00 explain用法
用法比较简单,格式为:
explain select count(*) from forum_user_role
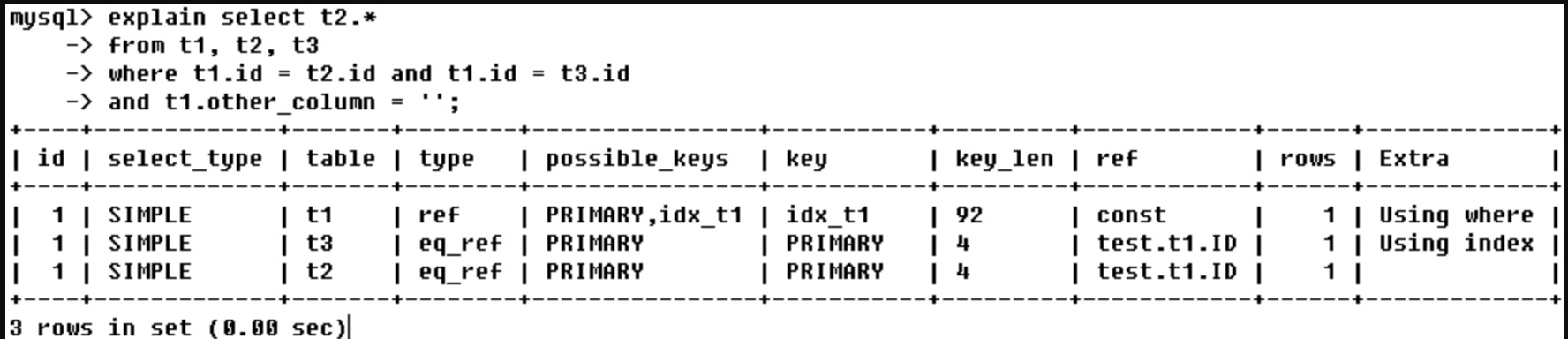
0x01 explain字段详解
1、select_type
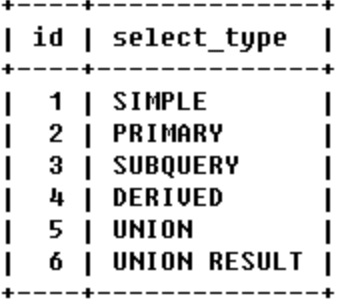
- SIMPLE:查询中不包含子查询或者UNION
- 查询中若包含任何复杂的子部分,最外层查询则被标记为:PRIMARY
- 在SELECT或WHERE列表中包含了子查询,该子查询被标记为:SUBQUERY
- 在FROM列表中包含的子查询被标记为:DERIVED(衍生)
- 若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在 FROM子句的子查询中,外层SELECT将被标记为:DERIVED
- 从UNION表获取结果的SELECT被标记为:UNION RESULT
2、type
-
具体参见参考资料。总结一下就是type为ALL则意味着全表遍历。type为NULL则意味不需遍历即可。
-
其余字段参考http://blog.csdn.net/leileixiaoshan/article/details/26108427链接即可,可以通过explain语句来进行对应的sql优化
五、参考资料
- http://blog.csdn.net/leileixiaoshan/article/details/26108427
- http://tech.meituan.com/mysql-index.html
- http://blog.csdn.net/idber/article/details/8096941
- http://www.cnblogs.com/ashou706/archive/2010/06/08/1754174.html
- http://www.cnblogs.com/morvenhuang/archive/2009/03/30/1425534.html
- http://blog.sina.com.cn/s/blog_673250f30101ol4f.html
- http://blog.csdn.net/v_JULY_v/article/details/6530142/
讨论题目
- 复合索引使用的目的是什么?
- 一个复合索引是否可以代替多个单一索引?
- 在进行哪些类型的查询时,使用复合索引会比较有效?
- 符合索引中索引列的排序原则是什么?
- 什么情况下不适合使用复合索引?
- 电商项目的库存设计,如何不卖超,取消订单把库存加回去,不能多加